UIの「正解」をAIにどう伝えるか?
いつもの医療が変わるアプリ「melmo」Android版の開発で正解画像を用いて、AIエージェントにUIの「見た目」を評価・自己改善させる仕組みを構築した話
この記事は、Medley(メドレー) Advent Calendar 2025 の20日目の記事です。
AIに「完了」と言われても、UIは崩れていた
「実装完了しました!」
AIエージェントが自信ありげにタスクの完了報告をしてくれたのでアプリをビルドして起動してみると、 そこには配置が意図した通りではないUIが表示されていました…(コレジャナイ)。 みなさんも、AIエージェントへ依頼したタスクでこんな経験はありませんか?
私はメドレーに入社して以来、いつもの医療が変わるアプリ「melmo1」 の開発に携わっています。 Androidアプリの開発では、従来のXMLベースの画面実装を宣言的UIのJetpack Composeへ移行するプロジェクトを日々の改善作業と並行して進めています。 この移行作業において、AIエージェントは非常に強力なパートナーですが、私の頭を悩ませていたのが完成度の低いUIコードが量産されることでした。
「意図した通りに見えなければ、それはバグである」 というのがUI開発の宿命です。 「ボタンの位置が違います」「XXの余白が足りません」とテキストでフィードバックを繰り返すAIとの不毛な会話を減らしたいという願いから、 AI自身がUIの間違いに気づける方法はないか?を模索し始めました。
ロジックはテスト、では「見た目」は?
論理的なコードの正しさは、事前にテストコードを用意し、AIエージェントに「テストが通るまでコード修正を繰り返す」よう指示することで、ある程度判断できます。 しかし、UIコードとなると、ボタンやテキストが画面上に存在しているかをテストでチェックすることはできても、実際に描画してみないと「意図した通りに見えているか」を判断することはできません。
「AIが自分で見て、自分で直す」。そんな人間のような振る舞いをさせるには、AIに 「視覚」 を与える必要があると考えました。
マルチモーダルの「目」
解決の糸口が見えたのは、AIエージェントからFigmaのデザインデータを参照する「Figma MCPサーバー」を試していたときでした。
Claude Code上で実行ログを眺めていると、「Read image …」 というRead タスクが走り、デザインデータを画像として読み込んで解析している様子が目に止まりました。 マルチモーダル対応モデルであれば、画像を直接見てその内容を理解できる能力を持っています。当たり前のことですが、これは重要な気づきでした。
このヒントから、AI自身が「実装した画面のスクリーンショット画像」と「正解のデザイン画像(ベースライン)」を見比べることができれば、 UIの間違いに気づけて「正解」へ近づけていく自律的な改善サイクルが作れるのではないか? と仮説を立て、画像を用いてAIに視覚を与える方針を固めました。
5分待つか、30秒で終わらせるか
方針が決まれば、「どうやってAIにスクリーンショット画像を撮らせるか」という仕組み化です。
最も単純な方法は、私たちが作業している手順と同じように「アプリをビルドして、エミュレータを起動し、目的の画面まで遷移してキャプチャする」ことでしょう。 E2Eテストではこの方法が一般的に採用されていますが、この方法は見送りました。Androidアプリ開発者なら共感してもらえると思いますが、このサイクルを回すには速くても数分かかります。 AIが自律的に回すとはいえ、タスク完了までの速さに関係してくるので、より軽量な実行環境が必要でした。
そこで今回は、テスト内でCanvasに描画されたスクリーンショットを生成するアプローチを採用することにしました。 この方法ならアプリ全体をビルドする必要がないため、対象のモジュール2に限定してテストを高速に(数秒〜数十秒で)繰り返すことが可能です。 これはAndroid開発におけるVRT(Visual Regression Testing)の一般的な手法であり、AIエージェントでも十分に扱える範囲だと判断しました。
1.ビルド → 2.テスト(撮影)→ 3.評価 → 4.修正 → .. // 1サイクルが高速画像比較による自律的な改善サイクルの構築
前章の「テストで高速に撮影し、画像比較でAI自身に判定させる」という方針に基づき、 実際のAndroidアプリ開発でどう実現したのか?を4つのステップと、そこで直面したチーム諸事情にまつわる課題と解決策について解説します。
1. テストで撮る(Robolectric + Roborazzi)
スクリーンショットの撮影には、Roborazziを採用しました。
エミュレータ不要でテストをJVM上で動かすRobolectric環境下での撮影が可能なOSSライブラリです。
最初はJetpack Compose標準搭載のAPI captureToImage を試しましたが、Robolectric環境下ではまだ使えませんでした。3
@RunWith(AndroidJUnit4::class)
class SampleScreenTest {
@get:Rule
val composeTestRule = createComposeRule()
@Test
fun captureSampleScreen() {
composeTestRule.setContent {
// 確認対象の画面を描画する
SampleScreen(state = SampleState(...))
}
// Roborazziでスクリーンショットを撮る
captureScreenRoboImage()
}
}このテストコードを実行すると、対象モジュールの build/outputs/roborazzi/ 配下に画面のスクリーンショットがPNG形式で出力されます。
また、AI自身がこのテストコードを迷わず生成できるよう、 私たちのプロジェクトでは「スナップショットツールの使い方」をドキュメントにまとめ、プロンプトのコンテキストとして渡せるように整備しました。
2. 正解のデザイン画像を用意する
AIが「自分の実装が正しいか」を判断するには、比較対象となる正解画像が必要です。 理想を言えばFigmaのデザインデータをそのまま正解として使いたいところですが、 私たちのプロジェクトはiOS版の画面デザインをもとにAndroid版も開発しているという事情があり、正解データとしては使えませんでした。
そこで今回の移行作業においては、「移行前(XML実装)の画面をエミュレータで動かして撮ったスクリーンショット」を正解画像とすることにしました。 しかし、この選択には新たに2つの技術的な壁が立ちはだかりました。
Robolectricとエミュレータで撮った画像のサイズが合わない
先に結論から伝えると、私が検証した中でRobolectricとサイズが完全に一致したのは「Pixel 5」のエミュレータのみでした。 Android Studioに用意されているPixel シリーズのうちPixel 5からPixel 9 Pro(当時の最新) までを一通り試しましたが、 Robolectricの内部のDPI計算において丸め誤差が生じるらしく、エミュレータの実際の出力サイズと1ピクセルでもズレてしまうと比較ができません。
| デバイス | エミュレータで撮ったサイズ | Robolectricで撮ったサイズ |
|---|---|---|
| Pixel 5 | 1080 x 2340 px | 1080 x 2340 px |
| Pixel 7 | 1080 x 2400 px | 1078 x 2399 px 👈 |
エミュレータで撮った画像にシステムバー領域が含まれてしまう
エミュレータのスクリーンショットには上下のシステムバー(時刻やナビゲーション)が含まれます。 しかし、Robolectricはコンテンツ領域しか描画されないので、これでは画像比較ができません。
そこでエミュレータで撮った画像のシステムバー領域を画像加工で強制的に黒塗り(マスク)する処理を行い、 Robolectric側の撮影処理で上下にダミーのシステムバー領域(余白)を加えて、黒背景で描画することにしました。
# Image MagickツールによるSystem barsの黒塗り例:
$ magick input.png -fill black -draw "rectangle 0,0 1080,135" -draw "rectangle 0,2274 1080,2340" output.png@Test
fun captureSampleScreen() {
composeTestRule.setContent {
SampleScreen(
// ダミーのシステムバー領域を確保
modifier = Modifier.fillMaxSize()
.background(Color.Black)
.windowInsetsPadding(WindowInsets(top = 49.dp, bottom = 24.dp))
state = SampleState(...)
)
}
captureScreenRoboImage()
}このように、泥臭いハックを重ねてようやく「比較可能な2枚の画像」を用意することができました。めでたし、めでたし(Figmaのデザインデータが使えれば…)
3. 構造的類似度(SSIM)で判定する
AIエージェントに画像比較のスキルを持たせるために、OSSのRust製ツール「dssim」を採用しました。 このツールはSSIM(Structural Similarity / 構造的類似度) というアルゴリズムに基づいており、人間の視覚特性に近い比較が可能です。
$ dssim baseline.png actual.png
0.11072981dssim が出力するのは「非類似度」のスコアです。0から1の間で、0に近いほど似ていることを意味します。
スコアの基準目安:
- 0.01以下: ほぼ完璧に一致
- 0.05以下: 人間の目にはほとんど同じ(このあたりを合格ラインとして目指したい)
- 0.10以下: わずかな違いがある
VRTの文脈ではodiffなどのピクセル差分ツールが一般的に使われますが、 私たちのプロジェクトではエミュレータとRobolectricの異なる環境下で撮った画像のコントラスト差異を許容する必要もあったため、構造的類似度が最適解でした。
また、このツールもAI自身が使いこなせるよう、私たちのプロジェクトではスナップショットツールの使い方のドキュメントに含めておきました。
4. AIへのプロンプトでループを回す
AIエージェントには以下のような指示を与え、自律的な改善を促しました。
> @foo/SampleFragment.kt をComposeの画面実装へ移行したいです。
移行後の画面にはスナップショットツールをテストに組み込んでください。
- @docs/compose-snapshot-tool.md
@baseline/ 配下にEmulatorから事前にキャプチャした既存のスクリーンショット画像があります。
- @baseline/SamplePage.png : 初期コンテンツ表示
- @baseline/SamplePage_Empty.png : コンテンツ無しの表示
必ず非構造的類似度による画像比較の結果が0.05以下になるまで繰り返して、固定データで同じ見た目のページを作成してください。こうして、エンジニアがXのタイムラインを見ながらコーヒーを飲んでいる間に、AIが「実装→撮影→評価→修正」の改善サイクルを自律的に回してくれる仕組みが出来上がりました。
AIは「正解」にどこまで近づけたのか
前章では画像比較による自律的な改善サイクルを構築する方法を解説しました。
実際にAIエージェントはUIの「正解」をどこまで理解し、再現できたのか?移行作業を試した具体的な画面での検証結果を公開します。※画像に名前が入っている部分は公開向けにマスク処理を施しました
検証は、以下の環境で行いました。
- コーディングツール:Claude Code (2025年10月実施時点の最新バージョン)
- モデル: Claude Sonnet 4.5
- 評価ツール: dssim 3.4.0
- 実行環境: macOS
ケース1: 医科診療所向けの資料一覧画面
正解画像は、資料ありの表示パターンと資料なしの表示パターンの2枚を用意しました。

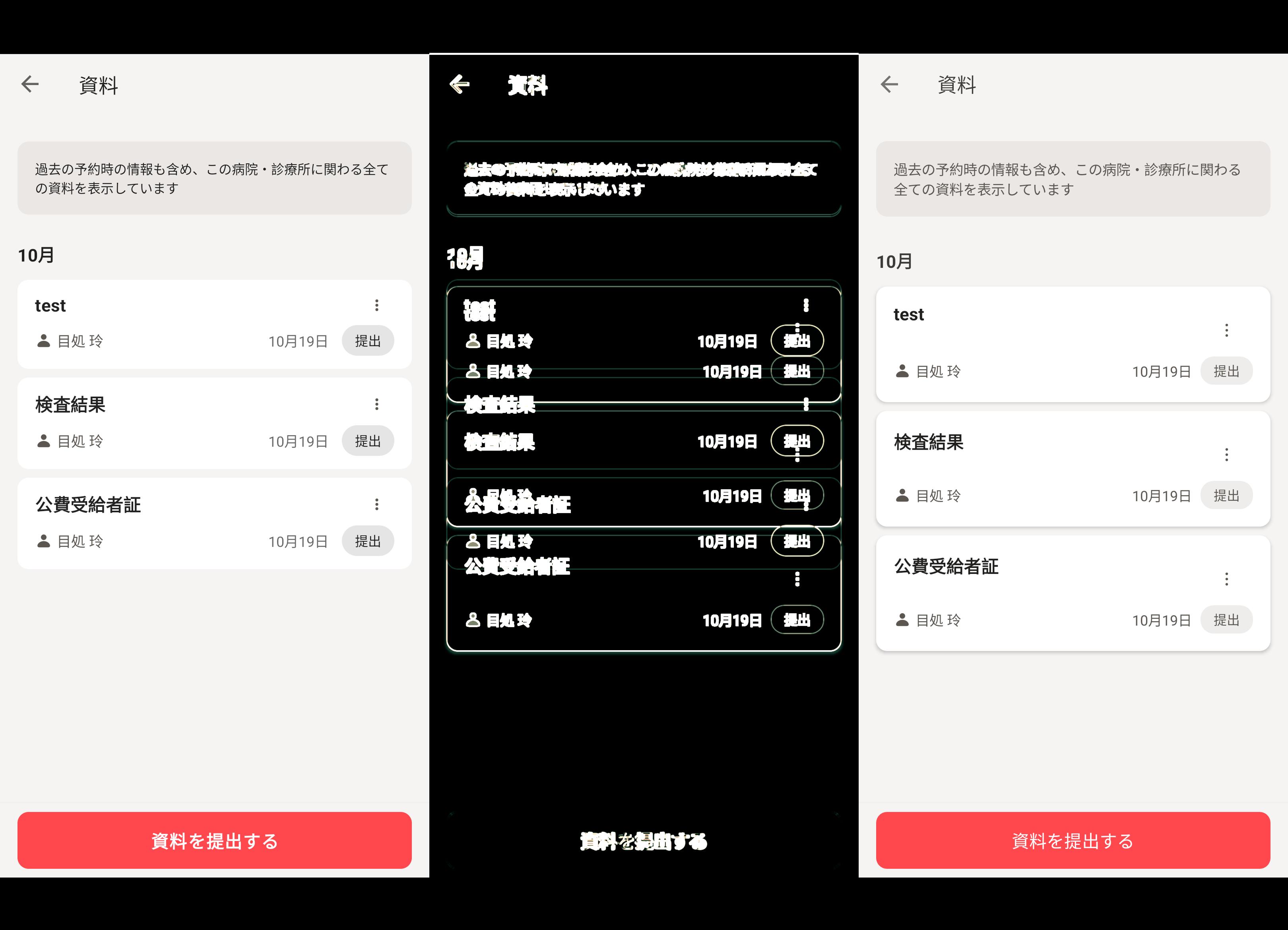
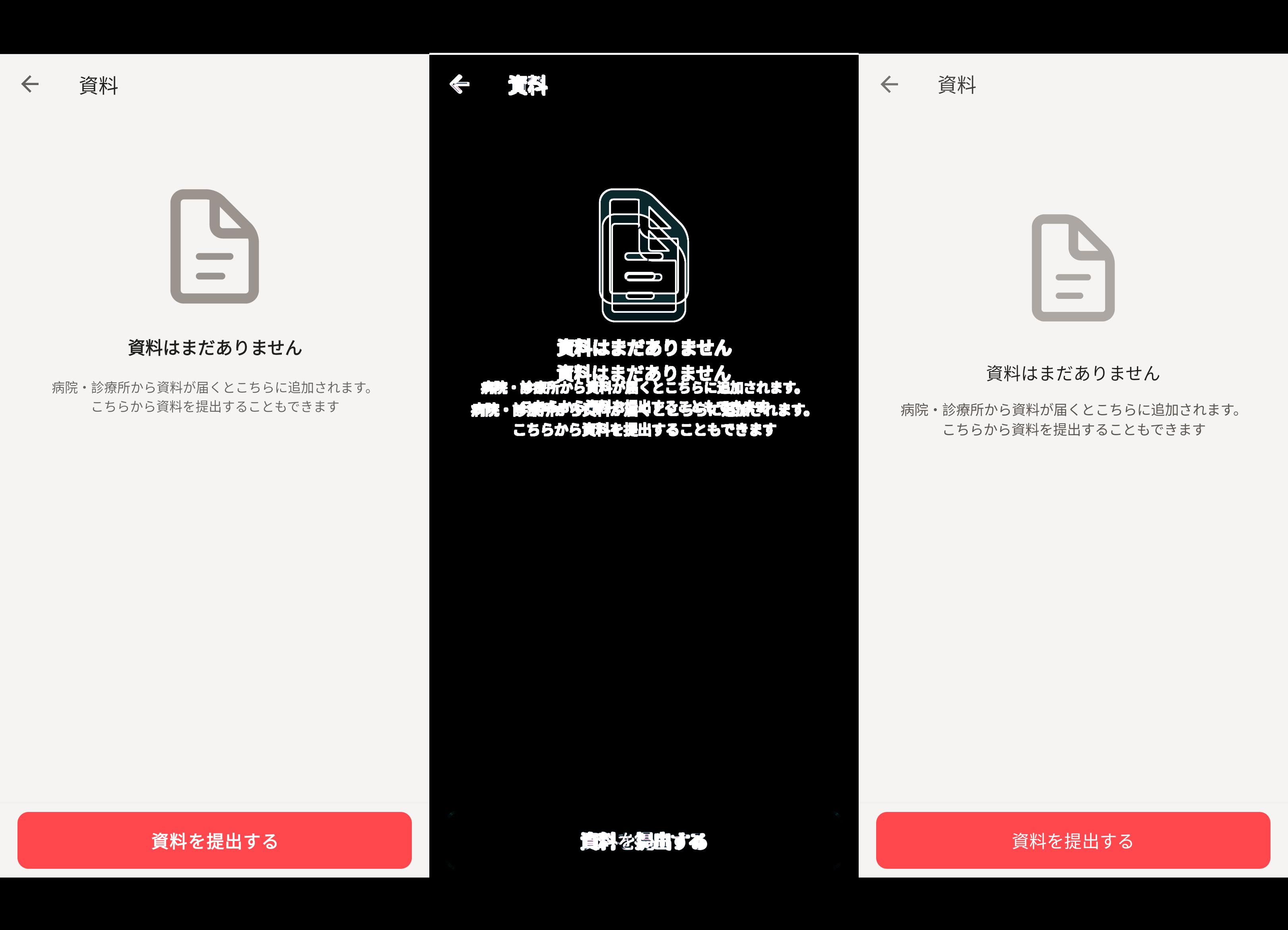
改善サイクルは回せているが、閾値には届かずタスク停止。
AIは、人間の目には区別がつかないレベルと言っているが、明らかに違いは分かる。
ケース2: 医科診療所向けの予約詳細画面
正解画像は、初期表示パターンとスクロール後の表示パターンの2枚を用意しました。

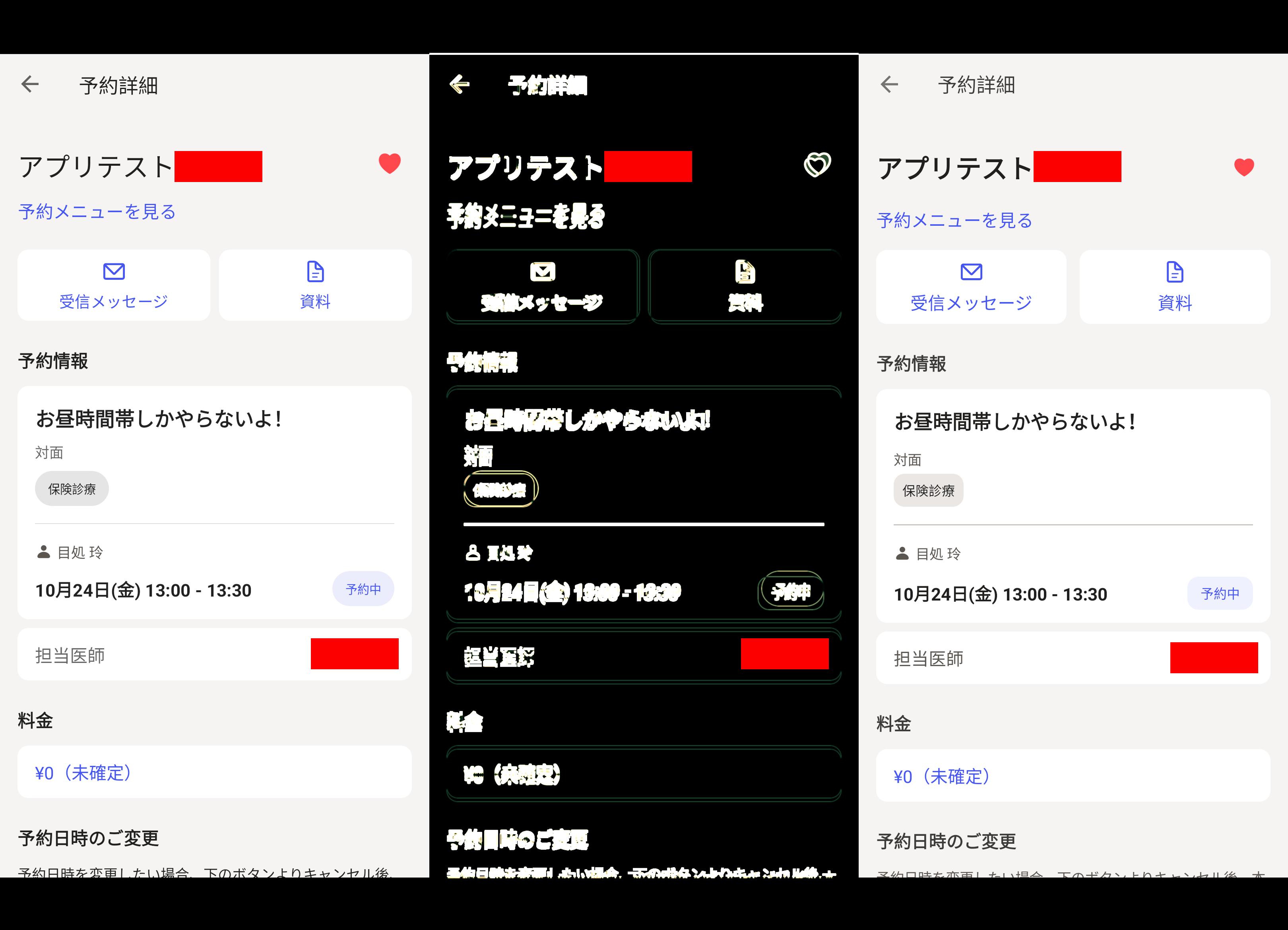
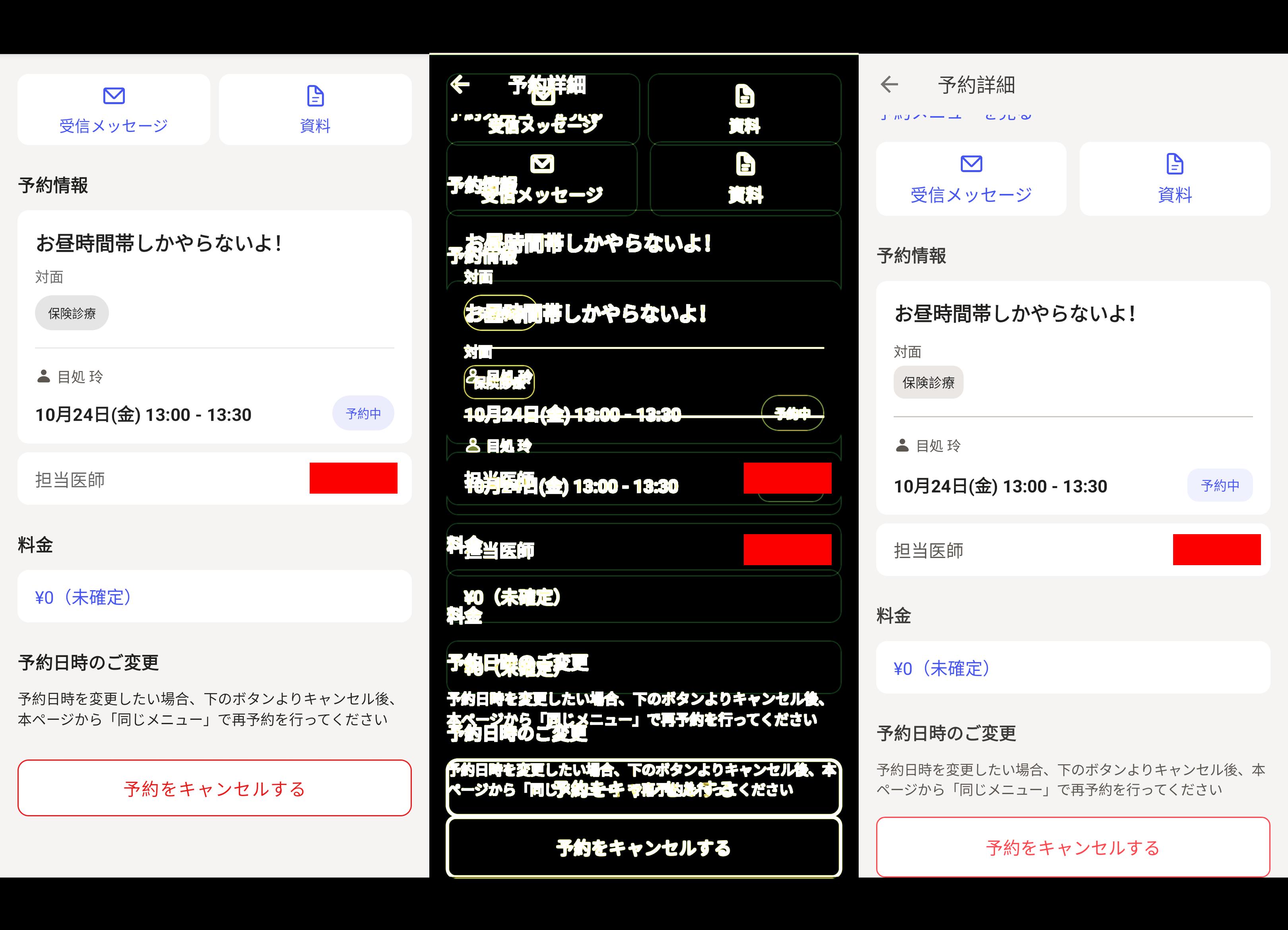
こちらも改善サイクルは回せているが、閾値には届かずタスク停止。
スクロール後の表示パターンについては、フォーカスが下部ボタンになっており、基準となるスクロール位置がそもそも間違っていた。
結論:完成度は上がったが、あと一歩が届かない
人間の目にはほぼ同じに見えるレベル「非類似度 0.05以下」を目指しましたが、 今回検証した中では 0.1付近までの改善が限界であり、そこからの微細な調整にはまだ人の手が必要であるという現実も見えてきました。
今回は「既存のXML画面をJetpack Composeで再現する」という、いわば正解の仕様がコードとして存在している有利な条件下での検証でした。 それでも、画像比較だけでは埋められない「あと一歩」の壁はなかなか高そうです。
しかし、開発者が確認する前に「AI自身が可能な限り最善を尽くす」という自律的な改善サイクルを確立できたことは、開発効率の向上に向けて一歩前進となりました。 今後のAIモデルの進化次第では、この精度はさらに向上すると期待して、この方向性での模索を続けていきたいと思います。
終わりに
このブログを書いている最中に、ちょうど「Android Studio Otter 3 Feature Drop | 2025.2.3」のプレビュー版が公開されました。 その中で追加された「Match your UI with a target image」というGeminiの新機能は、今回試したアプローチと似ています。 説明文に「エージェントがターゲット画像に可能な限り近づける」と書いてあり、どのように評価しているのか気になりますね。
さて、明日の21日目は、@gongon282828 さんによる「Datadog Workflow AutomationでAPMエラーからGitHub Issueを自動生成してみた格闘した話」です。
お楽しみに!🎄🎅
メドレーでは生成 AI 利用のガイドラインが社内で展開されており、各部門の業務ではそのガイドラインに沿って利用をしています。